WebScrapBook 作成者: Danny Lin
Capture web pages to local device or backend server for future retrieval, organization, annotation, and edit.
7,077 人のユーザー7,077 人のユーザー
拡張機能メタデータ
スクリーンショット


この拡張機能について
WebScrapBook is a browser extension that captures the web page faithfully with various archive formats and customizable configurations, for future retrieval, organization, annotation, and editing. This project inherits from legacy Firefox add-on ScrapBook X.
Features:
1. Capture faithfully: A web page shown in the browser can be captured without losing any subtle detail. Metadata such as source URL and timestamp are also recorded.
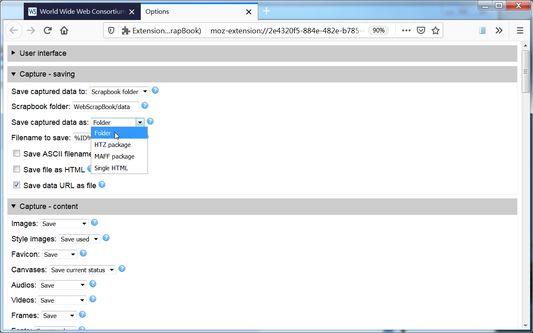
2. Customizable capture: WebScrapBook can save selected area in a page, save source page (before processed by scripts), or save page as a bookmark. How to capture images, audio, video, fonts, frames, styles, scripts, etc. are also customizable. A web page can be saved as a folder, a ZIP-based archive file (HTZ or MAFF), or a single HTML file.
3. Page editing: A web page can be highlighted, annotated, or edited before or after a capture.
4. Organizable collections: Captured pages can be organized in the browser sidebar using one or more scrapbooks, and each scrapbooks holds a hierarchical tree structure to organize data items. Notes using HTML or markdown format can also be created and managed. (*)
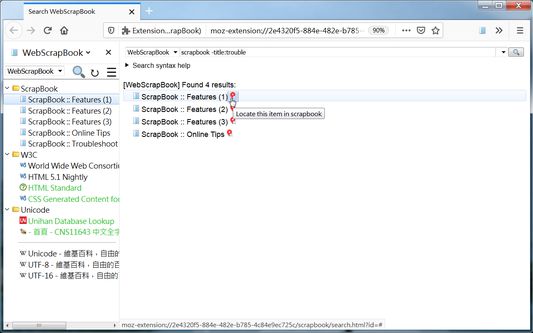
5. Fulltext searching: Each scrapbook can be further indexed for a rich-feature search (using title, fulltext, comment, source URL, create time, modify time, etc.). (*)
6. Remote access: Captured data can be hosted with a central backend server and be read or edited from other devices. Alternatively, a scrapbook can generate a static site index and be distributed as a static web site. (*)
7. Mobile support: WebScrapBook supports mobile browsers such as Firefox for Android and Kiwi browser. You can capture and edit the web page from a mobile phone or tablet.
8. Legacy ScrapBook support: Scrapbooks created from legacy ScrapBook or ScrapBook X can be converted into WebScrapBook-compliant format for usage. (*)
* All or partial functionality of a starred feature above requires a running collaborating backend server, which can be easily set up using PyWebScrapBook.
* An HTZ or MAFF archive file can be viewed using the built-in archive page viewer, using PyWebScrapBook or other assistant tools, or by opening the index page after unzipping.
See Also:
* For further information and frequently asked questions, visit the documentation wiki.
* For better discussion, please report an issue to the source repository.
Features:
1. Capture faithfully: A web page shown in the browser can be captured without losing any subtle detail. Metadata such as source URL and timestamp are also recorded.
2. Customizable capture: WebScrapBook can save selected area in a page, save source page (before processed by scripts), or save page as a bookmark. How to capture images, audio, video, fonts, frames, styles, scripts, etc. are also customizable. A web page can be saved as a folder, a ZIP-based archive file (HTZ or MAFF), or a single HTML file.
3. Page editing: A web page can be highlighted, annotated, or edited before or after a capture.
4. Organizable collections: Captured pages can be organized in the browser sidebar using one or more scrapbooks, and each scrapbooks holds a hierarchical tree structure to organize data items. Notes using HTML or markdown format can also be created and managed. (*)
5. Fulltext searching: Each scrapbook can be further indexed for a rich-feature search (using title, fulltext, comment, source URL, create time, modify time, etc.). (*)
6. Remote access: Captured data can be hosted with a central backend server and be read or edited from other devices. Alternatively, a scrapbook can generate a static site index and be distributed as a static web site. (*)
7. Mobile support: WebScrapBook supports mobile browsers such as Firefox for Android and Kiwi browser. You can capture and edit the web page from a mobile phone or tablet.
8. Legacy ScrapBook support: Scrapbooks created from legacy ScrapBook or ScrapBook X can be converted into WebScrapBook-compliant format for usage. (*)
* All or partial functionality of a starred feature above requires a running collaborating backend server, which can be easily set up using PyWebScrapBook.
* An HTZ or MAFF archive file can be viewed using the built-in archive page viewer, using PyWebScrapBook or other assistant tools, or by opening the index page after unzipping.
See Also:
* For further information and frequently asked questions, visit the documentation wiki.
* For better discussion, please report an issue to the source repository.
144 人のレビュー担当者が 4 と評価しました
権限とデータ
必要な権限:
- ファイルのダウンロードおよびブラウザーのダウンロード履歴の読み取りと変更
- ブラウザーのタブへのアクセス
- ナビゲーション中のブラウザーアクティビティへのアクセス
- すべてのウェブサイトの保存されたデータへのアクセス
任意の許可設定:
- 位置情報へのアクセス
詳しい情報
- アドオンリンク
- バージョン
- 2.25.0
- サイズ
- 507.78 KB
- 最終更新日
- 12日前 (2026年3月24日)
- バージョン履歴
- タグ
- コレクションへ追加