WebScrapBook ద్వారా Danny Lin
Capture web pages to local device or backend server for future retrieval, organization, annotation, and edit.
ఈ పొడగింతను వాడుకోడానికి మీకు Firefox ఉండాలి
పొడిగింత మెటాడేటా
తెరపట్లు


ఈ పొడిగింత గురించి
WebScrapBook is a browser extension that captures the web page faithfully with various archive formats and customizable configurations, for future retrieval, organization, annotation, and editing. This project inherits from legacy Firefox add-on ScrapBook X.
Features:
1. Capture faithfully: A web page shown in the browser can be captured without losing any subtle detail. Metadata such as source URL and timestamp are also recorded.
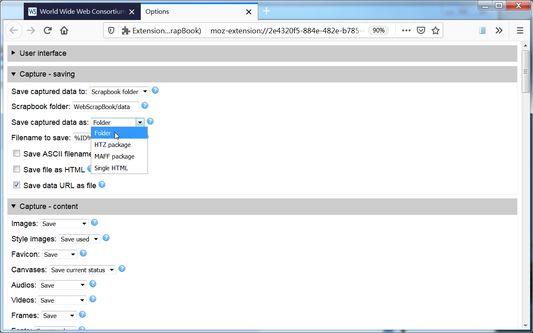
2. Customizable capture: WebScrapBook can save selected area in a page, save source page (before processed by scripts), or save page as a bookmark. How to capture images, audio, video, fonts, frames, styles, scripts, etc. are also customizable. A web page can be saved as a folder, a ZIP-based archive file (HTZ or MAFF), or a single HTML file.
3. Page editing: A web page can be highlighted, annotated, or edited before or after a capture.
4. Organizable collections: Captured pages can be organized in the browser sidebar using one or more scrapbooks, and each scrapbooks holds a hierarchical tree structure to organize data items. Notes using HTML or markdown format can also be created and managed. (*)
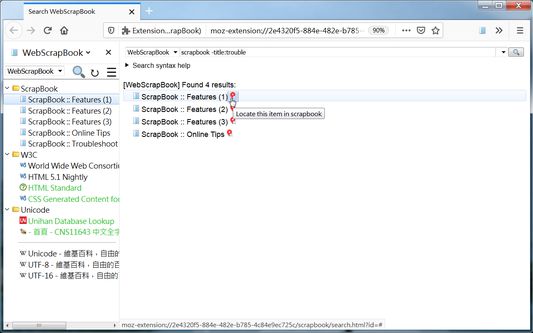
5. Fulltext searching: Each scrapbook can be further indexed for a rich-feature search (using title, fulltext, comment, source URL, create time, modify time, etc.). (*)
6. Remote access: Captured data can be hosted with a central backend server and be read or edited from other devices. Alternatively, a scrapbook can generate a static site index and be distributed as a static web site. (*)
7. Mobile support: WebScrapBook supports mobile browsers such as Firefox for Android and Kiwi browser. You can capture and edit the web page from a mobile phone or tablet.
8. Legacy ScrapBook support: Scrapbooks created from legacy ScrapBook or ScrapBook X can be converted into WebScrapBook-compliant format for usage. (*)
* All or partial functionality of a starred feature above requires a running collaborating backend server, which can be easily set up using PyWebScrapBook.
* An HTZ or MAFF archive file can be viewed using the built-in archive page viewer, using PyWebScrapBook or other assistant tools, or by opening the index page after unzipping.
See Also:
* For further information and frequently asked questions, visit the documentation wiki.
* For better discussion, please report an issue to the source repository.
Features:
1. Capture faithfully: A web page shown in the browser can be captured without losing any subtle detail. Metadata such as source URL and timestamp are also recorded.
2. Customizable capture: WebScrapBook can save selected area in a page, save source page (before processed by scripts), or save page as a bookmark. How to capture images, audio, video, fonts, frames, styles, scripts, etc. are also customizable. A web page can be saved as a folder, a ZIP-based archive file (HTZ or MAFF), or a single HTML file.
3. Page editing: A web page can be highlighted, annotated, or edited before or after a capture.
4. Organizable collections: Captured pages can be organized in the browser sidebar using one or more scrapbooks, and each scrapbooks holds a hierarchical tree structure to organize data items. Notes using HTML or markdown format can also be created and managed. (*)
5. Fulltext searching: Each scrapbook can be further indexed for a rich-feature search (using title, fulltext, comment, source URL, create time, modify time, etc.). (*)
6. Remote access: Captured data can be hosted with a central backend server and be read or edited from other devices. Alternatively, a scrapbook can generate a static site index and be distributed as a static web site. (*)
7. Mobile support: WebScrapBook supports mobile browsers such as Firefox for Android and Kiwi browser. You can capture and edit the web page from a mobile phone or tablet.
8. Legacy ScrapBook support: Scrapbooks created from legacy ScrapBook or ScrapBook X can be converted into WebScrapBook-compliant format for usage. (*)
* All or partial functionality of a starred feature above requires a running collaborating backend server, which can be easily set up using PyWebScrapBook.
* An HTZ or MAFF archive file can be viewed using the built-in archive page viewer, using PyWebScrapBook or other assistant tools, or by opening the index page after unzipping.
See Also:
* For further information and frequently asked questions, visit the documentation wiki.
* For better discussion, please report an issue to the source repository.
మీ అనుభవమును రేట్ చేయండి
ఈ డెవలపర్కు మద్దతు ఇవ్వండి
ఒక చిన్న విరాళం ఇచ్చి ఈ పొడగింత నిరంతర అభివృద్ధికి తోడ్పడమని దీని తయారీదారు మిమ్మల్ని కోరుతున్నారు.
అనుమతులుఇంకా తెలుసుకోండి
ఈ పొడిగింతకు ఇవి కావాలి:
- ఫైళ్లను దించుకోవడం, విహారిణి దింపుకోలు చరిత్రను చూడడం సవరించడం
- విహారిణి ట్యాబులను చూడటం
- నావిగేషన్ సమయంలో విహారిణి కార్యకలాపాన్ని చూడటం
- అన్ని వెబ్ సైట్లలో మీ డేటాను చూడటం
ఈ పొడిగింత వీటి కొరకు కూడా అడగవచ్చు:
- మీ స్థానాన్ని చూడండి
మరింత సమాచారం
- పొడిగింత లంకెలు
- వెర్షన్
- 2.18.5
- పరిమాణము
- 534.41 KB
- చివరిగా నవీకరించినది
- 2 రోజులు క్రితం (22 ఏప్రి. 2025)
- సంబంధిత వర్గాలు
- లైసెన్స్
- మొజిల్లా పబ్లిక్ లైసెన్స్ 2.0
- వెర్షన్ చరిత్ర
- ట్యాగులు
సేకరణకు జోడించు
Danny Lin నుండి మరిన్ని పొడగింతలు
 ఇంకా రేటింగులు ఏమీ లేవు
ఇంకా రేటింగులు ఏమీ లేవు- ఇంకా రేటింగులు ఏమీ లేవు
- ఇంకా రేటింగులు ఏమీ లేవు
- ఇంకా రేటింగులు ఏమీ లేవు
- ఇంకా రేటింగులు ఏమీ లేవు
- ఇంకా రేటింగులు ఏమీ లేవు